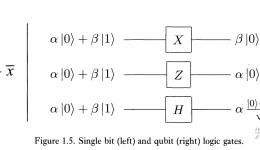
|
作者:Vitaliy llyukha 编译:青牛 您能否已经想过如作甚营业和利用法式开辟挑选最好的大数据引擎?大数据软件市场是庞大的,合作剧烈的,布满了看似很是类似的软件。 当前,大数据是企业软件开辟和补充中最需要的之一。大数据技术的高度提高是由于数据量的快速和延续增加引发的现象。 必须检查,机关和处置海量数据阵列,以供给所需的带宽。数据处置引擎在用于移动利用法式的技术仓库中获得了越来越多的利用,等等。 那末,什么大数据框架将是2020年的最好挑选?您应当为产物挑选什么?让我们找出答案!  顶级大数据框架:技术公司将在2020年挑选什么?现在,能够没有单一的大数据软件没法处置大量数据。已经建立了特别的大数据框架来实现和支持此类软件的功用。它们有助于快速处置和构建大量实时数据。 什么是最好的大数据工具?今朝市场上有很多很棒的大数据工具。为了进入前10名,我们必须解除很多值得一提的著 名处理计划一Kafka和Kafka Streams, Apache TEZ, Apache Impala, Apache Beam,Apache Apex。可是,我们只挑选代表:
我们已经停止了透彻的分析,以组成将在2020年景为支流的这些顶级大数据框架。让我们一路来看看!  1. Hadoop,它在2020年照旧会风行吗?Apache Hadoop是大数据存储和处置的反动性处理计划。大大都大数据软件都是围绕Hadoop构建的或与Hadoop兼容的。这是来自Apache Software Foundation的开源项目。 什么是Hadoop框架?Hadoop很是合适牢靠,可扩大的散布式计较。可是,它也可以用作通用文件存储。它可以存储和处置PB的数据。该处理计划包括三个关键组件:
Hadoop若何切确地处理现代DBMS的内存题目? Hadoop在交互式数据库和数据存储之间利用中心层。其性能随着数据存储空间的增加而增加。为了进一步扩 展,您可以将新节点增加到数据存储中。 Hadoop可以存储和处置很多PB的信息,而Hadoop中 最快的进程只需几秒钟即可运转。它还制止在处置进程中对已存储在HDFS系统中的数据停止任何编辑。 媒体对“Hadoop的灭亡”的热议背后能否有何意图?第一次问世时是反动性的,它催生了一个围绕着它的产业链。现在,大数据正在迁移到云中,而且有很多关于灾难的说法。Hadoop终结了吗?斟酌一下,大大都数据都存储在HDFS中,而且照旧需要用于处置或转换它的工具。 Hadoop照旧是一个强大的批处置工具, 可以与大大都其他大数据分析框架集成。它的组件: HDFS,MapReduce和YARN对行业自己是不成或缺的。是以,看起来它不会很快消失。 可是,虽然Hadoop无疑很受接待,但技术进步提出了新的方针和要求。更多高级替换品正逐步进入市场,以抢占市场份额(我们将进一 步会商其中的一些)  2. MapReduce。这个大数据搜索引擎会过期吗?MapReduce是Hadoop框架的搜索引擎。它最早是由Google于2004年作为并行处置大量原始数据量的算法而引入的。后来,它成为了我们现在所知的MapReduce。 该引擎将数据视为条目,并分三个阶段处置它们: 1.舆图(数据的预处置和过滤)。 2.随机播放(工作节点对数据停止排序,每个节点对应一个输出键,这是舆图功用发生的)。 3.精简(精简功用由用户设备,并为零丁的输出数据组界说终极成果)。 一切值中的大大都由Reduce返回(函数是MapReduce使命 的终极成果)。MapReduce供给数据的自动并行化,高效的平衡和故障平安性能。 多年来,它一向是该行业的主食,并与其他著名的大数据技术一路利用。 可是MapReduce可以替换,特别是Apache Tez。它是高度可定制的,而且速度更快。它利用YARN停止资笔莆理,是以资本效力更高。 3.SPRAK还是之前那样强大的工具?Apache Spark继续为最好的大数据框架。与Apache Hadoop相比,它是一个开放源代码框架,是作为更高级的处理计划而建立的。最初的框架是为处置大数据而明白构建的。这两种处理计划之间的首要区分在于数据检索模子。  Apache Spark一Computerphile Hadoop将数据与MapReduce算法的每个步调一路保存在硬盘上。当Spark履行一切操纵时,将利用随机存取存储器。是以,Spark显现 了快速的性能,并答应处置大量数据流。Spark的功用支 柱和首要特征是高性能和故障平安性。 它支持四种说话:
它包括五个组件:焦点和四个与大数据停止优化交互的库。Spark SQL是用于结构化数据处置的四个公用框架库之一。利用DataFrame息争决Hadoop Hive请求的速度进步了100倍。 Spark的Sparkling Water 2.3.0是业界最好的Al实施之一。Spark还具有Streaming工具,可实时处置特定于线程的数据。现实上,该工具更多地是微批量处置器而不是流处置器,而且基准测试也证实了这一点。 最快的批量处置器或最大的流处置器? Spark的行为 更像是快速批量处置器,而不是像Flink,Heron或Samza这样的现实流处置器。假如您在批处置处置器中需要类似流的功用,那便可以了。大概,假如您需要高吞吐量的慢速流处置器。这是一个概念题目。  Spark开创人指出,处置每个微批处置的均匀时候仅需0.5秒。接下来是MLib,它是一种散布式机械进修系统,比Apache Mahout库快9倍。一样,最初一个库是GraphX,用于可伸缩处置图数据。 Spark凡是被以为是Hadoop的实时替换品。可以,可是与Hadoop生态系统中的一切组件一样,它可以与Hadoop和其他重要的大数据框架一路利用 。 4.HIVE 大数据分析框架Apache Hive由Facebook建立,旨在连系最风行的大数据框架之一的可扩大性。它是将SQL请求转换为MapReduce使命链的引擎。 该引擎包括以下组件:
Hive可以与Hadoop集成(作为办事器部分),以分析大数据量。这是逐一个基准测试,显现了Hive在Tez上的合作表示(越低越好)。  在最初公布十年后,Hive照旧是最常用的大数据分析框架之一。 Hive 3由Hortonworks于2018年公布。它将MapReduce替换为Tez作为搜索引擎。它具有机械进修功用,并与其他风行的大数据框架集成。 可是,在Hortonworks和Cloudera比来合并以后,一些人对该项目标未来感应担忧。Hive的首要合作对手Apache Impala由Cloudera刊行。 5.Storm ,是Twitter第一个大数据框架Apache Storm是另一个精采的处理计划,专注于处置大型实时数据流。Storm的首要功用是可伸缩性和停机后敏捷规复的才能。您可以在Java, Python, Ruby和Fancy的帮助 下利用此处理计划。 Storm具有几个元素,使其与类似物大为分歧。第一个是Tuple,它是支持序列化的关键数据暗示元素。然后是Stream,其中包括在Tuple中命名字段的计划。Spout从内部来历接收数据,从中构成元组,并将其发送到Stream。 还稀有据处置法式Bolt和Topolog y,即一包元素及其相关描写。连系在一路,一切这些元素都可以帮助开辟职员治理大量非结构化数据流。 说到性能,Storm供给了比Flink和Spark更好的提早。可是,它的吞吐量较差。比来,Twitter (Storm的首要支持者)转移到了一个新的框架Heron。风暴仍在利用Yelp的一样,雅虎,阿里巴巴,以及一些至公司等。到2020年,它仍将具有庞大的用户群和支持。 6. Samza,为Kafka建造的流处置器Apache Samza是与Kafka配合开辟的有状态流处置大数据框架。Kafka供给数据办事,缓冲和容错才能。该二重奏旨在用于需要快速单阶段处置的地方。借助Kafka,可以以较低的提早利用它。Samza还可在处置进程中保存部分状态,以供给额外的容错才能。 Samza专为Kappa系统结构(仅用于流处置管道)而设想,但可以在其他系统结构中利用。Samza利用YARN来协商资本。是以,它需要一个Hadoop集群才能工作,这意味着您可以依靠YARN供给的功用。 这个大数据处置框架是为Linkedin开辟的,eBay和TripAdvisor还将其用于讹诈检测。 Kafka利用了相当一部分代码来建立合作的数据处置框架Kafka流。总而言之,Samza是一 个强大的工具,擅擅长其用处。可是Kafka流可以完全取代它吗?只要时候会给出答案。 7.Flink,实在的夹杂大数据处置器。Apache Flink是用于流和批处置的强大的大数据处置框架。它最初是在2008年左右作为科学尝试的一部分而构想的,并于2014年左右起头开源。尔后一向遭到接待。 Flink具有很多风趣的功用和使人印象深入的新技术。它利用像Apache Samza这样的有状态流处置。可是它也可以停止ETL和批处置,效力很高。  最合适Lambda管道 对于简化同时需要流处置和批处置的系统结构而言,这是一个绝佳的挑选。它可以从提取的数据中提取时候戳,以建立更正确的时候估量和流数据分析的更好框架。它还具有机械进修的实现才能。 作为Hadoop生态系统的一部分, 它可以轻松集成到现有架构中。它具有与MapReduce和Storm集成的传统,是以您可以在其.上运转现有的利用法式。它对大数据具有杰出的可伸缩性。 Flink很是合适设想事务驱动的利用法式。您可以在其上设备检查点以在处置进程中发生故障时保存进度。Flink还与风行的数据可视化工具Zeppelin具有毗连性。 阿里巴巴利用Flink观察光棍节的消耗者行为和搜索排名。成果,销售额增加了30%。金融巨头ING利用Flink构建讹诈检测和用户告诉利用法式。此外,Flink还具有机械进修算法。 Flink无疑是使人兴奋的新大数据处置技术之一。可是,能够有来由不利用它。大大都科技巨头尚未完全接管Flink,而是挑选投资自己的具有类似功用的大数据处置引擎。例如,Google的Data Flow + Beam和Twitter的Apache Heron。同时,Spark和Storm继续具有 可观的支持和支持。总而言之,Flink是一 个框架,估计将在2020年增加其用户根本。 8.Heron,这个流处置器将成为下一个大题目吗?Heron,这是较新的大数据处置引擎之一。 Twitter将其开 发为Storm的新一取代换产物。它旨在用于实时渣滓邮件检测,ETL使命和趋向分析。 Apache Heron与Storm完全向后兼容,而且迁移进程简单。其设想方针包括低提早,杰出且可猜测的可伸缩性以及易于治理。开辟职员很是重视进程隔离,以便于调试和稳定天时用资本。Twitter的基准 显现,与Storm相比有了明显改良。  该框架仍处于开辟阶段,是以,假如您正在寻觅早日采用的技术,则能够合适您。经过与Storm的出色兼容性以及Twitter的强大支持,Heron可 能很快会成为下一个大题目。 9. KuduApache Kudu是使人兴奋的新存储组件。它旨在简化Hadoop生态系统中的一些复杂管道。它是一品种似于SQL的处理计划,旨在将随机读取温柔序读取和写入连系在一路。 专门的随机或顺序拜候存储可以更有用地到达其目标。Hbase的随机拜候扫描速度是后者的两倍,而具有Parquet的HDFS则可与批处置使命媲美。  没有简单的方式来停止具有适当速度和效力的随机温柔序读取。出格是对于需要快速不竭更新数据的情况。直到苦都。它旨在与Hadoop生态系统的大大都其他大数据框架集成,特别是Kafka和lmpala。 在Kudu.上建立的项目 Kudu今朝用于华尔街的市场数据讹诈检测。究竟证实,它出格合适处置具有频仍更新的分歧数据流。这对于实时广告分析也很是有用,由于它速度快且供给了出色的数据可用性。 中国手机巨头小米挑选了Kudu来收集毛病报告。主如果由于它具有简化和简化数据管道以进步查询和分析速度的才能。  10. Presto,大数据查询引擎,用于小数据查询对于较小的使命,Presto是 Apache Hive的一种更快,更灵活的替换计划。Presto于2013年作为开放源代码公布。它是一种自顺应,灵活的查询工具,适用于具有分歧存储范例的多租户数据情况。  行业巨头(例如Amazon或Netflix) 对其停止开辟或对该大数据框架做出进献。Presto具有 联邦结构,各类百般的毗连器以及很多其他功用。 最初的设想要求之一是可以分析较小的数据子集(在50gb 一 3tb范围内)。对于该数据范围的描写性分析很是方便。 若何挑选大数据技术?一个辣手的题目。综上所述,可以必定地说,数据处置框架中没有最好挑选。每小我都有其优点和弱点。而且,某些处理计划供给的成果严酷取决于很多身分。 按照我们的经历,利用分歧工具的夹杂处理计划结果最好。大数据框架市场上的各类报价使精通技术的公司可以挑选最合适的工具来完成使命。 您能否照旧想晓得哪类框架最合适大数据?虽然我们之前已经以正确的方式回答了这个题目。那些照旧感爱好的人,我们以为什么是大数据框架最有用,我们将它们分为三类。
可是,我们再次夸大这一点。最好的框架是合适当前使命的框架。 虽然现今有很多框架,可是在大大都开辟职员中,只要少数很是受接待和需要。在本文中,我们斟酌了10个顶级大数据框架和库,这些框架和库势必在行将到来的2020年连结领先职位。 大数据软件市场无疑是一个合作剧烈且使人困惑的范畴。不乏新奇风趣的产物以及创新功用。我们希望这个大数据框架列表可以帮助您停止导航。 |



 微信扫一扫
微信扫一扫