前言比来有很多人问我,大数据专业有什么好的毕设项目,我就简单的答复了一下。也有间接问我要源码的....  所以就抽暇写一写自己结业设想的一个思绪,大数据是我练习自学的,这个思绪是我当初自己想的,就当做一份参考吧。 在我结业那年,同学们结业设想大多都是以Java说话开辟的各类治理系统、xx商城为主,包括我刚起头的想法也是这样的。这也是计较机专业很常见的结业设想选题。 这类挑选的益处就是简单,网上模板多。脱手才能强的同学,间接去github上拉下来历码,稍微点窜一下,一个结业设想项目就完成了。脱手才能衰的同学,也可以利用钞才能低本钱完成。 至于弱点嘛,就是这类毕设太常见了,除非UI设想和思绪出格出彩,让教员眼前一亮。要否则孤陋寡闻的教员,就会带着一颗毫无波涛的心里,用空洞的眼神看完你的演示,机械般的给你打下一个及格分。 固然,对于大部分同学的心里想法就是:能过就行。也有的同学担忧,自己的毕设项目和其他同学的重合度很高,教员能够会问一些细节(希奇怪僻)的题目。所以,「毕设最好还是自己做,就算找的模板,也要把技术和架构搞清楚」。 同时,想要做一个与众分歧的毕设,在技术上也一定要“花里胡哨”。 大数据毕设思绪大数据偏向的毕设,归根结柢还是基于大数据平台停止构想。对于治理系统、商城这类项目毕设来说,我们面向的是编程说话,而大数据首要还是还是面向平台。就像你一说大数据,他人接着就说,大数据...就是阿谁Hadoop吗? 是的。虽然这个回答很全面,可是对于大数据毕设来说,就是基于Hadoop来发散延长。 我学的不是大数据专业,也曾有成为一位优(C)秀(V)的Java开辟的胡想。后来,17年练习鬼使神差就打仗到大数据,并起头自学大数据,所以在18年结业的时辰,就基于大数据完成了结业设想。这里就简单说一下当初我的结业设想流程。
就很简单,很简单。大师可以在上面的思绪上停止扩大。下面就展开说一下具体步调。 大数据毕设理论关于下文中提到的一些大数据概念,可以参考之前写的一篇大数据的文章。 0. 数据预备大数据,大数据,数据必定是大的一望无边。那多大才算大?自从18年负责一天1w亿条数据的接入、存储、处置工作以后,我就飘了~ 经常同事告诉我说,要接入一个大数据量的文件接口,我问他几多,他说一天一百亿条,我一般会轻飘飘地说一句,一百亿,算多吗 ~~~ 实在,对于结业设想来说,数据量并不需要那末大,数据在大数据平台中的流转,以此来模拟大数据中的ETL和实时处置,从而表现数据的代价。 那末,数据从那里获得呢? 方式1,我们可以写一个法式来天生一些测试数据,可是这样的话,数据重合度太高,很难表现出数据分析代价。那末就采用方式二,开辟爬虫停止收集网上的数据。 那时我用Java开辟了一个爬虫,收集了163w条POI位置数据,存到了MySQL中,完成了数据的预备工作。爬虫的开辟回是保举用Python,17年我还不会Python,后来18年起头进修Python,后来又做了很多爬虫开辟工作,再后来写了爬虫系列由浅入深的进修文章,大师也可以参考一下。 1. 大数据平台搭建欲抬手摘星望月,必先高山起高楼。 上面也说了,大数据还是围绕着平台来搞。那时我在笔记本上搭建了三台centos系统的虚拟机,首要用来搭建下面的集群。 在集群搭建之前,需要完成以下操纵系统和情况的设置。
Hadoop - 根本焦点Hadoop集群作为大数据根本扶植,同时也是大数据焦点。其HDFS供给了散布式存储,Yarn供给了计较资本。 假如是毕设的话,可以挑选「一主两从」的架构,即一个NameNode和两个DataNode的架构。假如想要玩的花一点,就挑选HA高可用架构,即两主两从,这里就需要四台虚拟机。 关于HA,就是两个NameNode,可是一个NN处于工作状态(active),一个NN处于待命状态(standby)。你可以kill掉active的NN,然后让standby的NN接收集群。 关于HA,在大数据是到处可见的。在Hadoop生态中,集群中的多NN和多DN是HA,HDFS的副本机制也是HA,这一块在论文中还是能表现很多工具的。 下面就是Hadoop集群的NN和DN的根基信息。 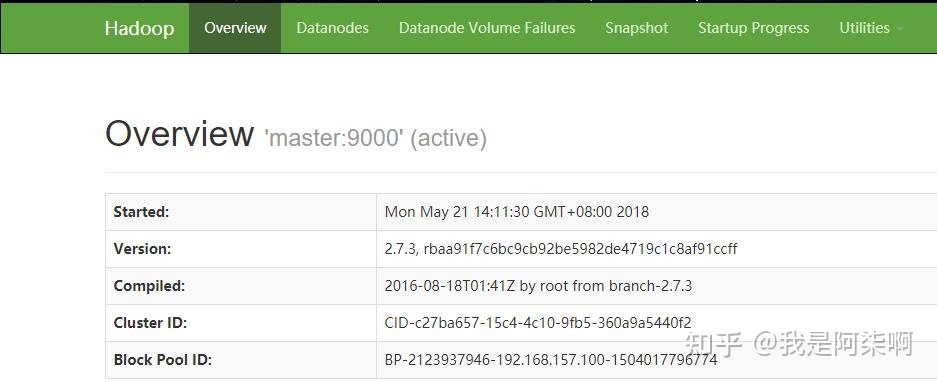  Hive - 离线分析Hive在我的毕设中的脚色就是一个数据分析的工具,首要表述的是大数据ETL中L阶段,以及大数据平台的离线分析部分。 Hive是一个数据仓库,关于它的感化就是对HDFS上的数据停止离线分析,虽然它不是数据库,可是大师可以把它当做数据库来用。这里其他根本的概念就不多先容了。 时至本日,也有很多hive的平替产物,例如号称比hive快800倍的clickhouse,以及druid,可是在利用处景方面和hive还是有一定收支的,有爱好的可以去领会一下。 大数据在数仓方面,有很多值得玩的平台架构和一些根基概念,ETL描写的就是基于数据仓库停止的数据处置进程。 Spark、Kafka - 实时计较现在提到实时计较,能够大师首先会想到flink。简直,flink在开源实时范畴方面绝对算是TOP了。18年的时辰,实时处置还是SparkStreaming利用的比力普遍。所以那时我安装的是Spark集群,来模拟的实时计较。 实在Spark/flink集群都是可以不搭建的,在Spark集群上运转法式属于standlone形式,假如利用yarn形式只需要有客户端便可以了。Spark法式运转在yarn上,能对cpu和内存停止资本隔离,而且不需要要零丁保护一个Spark集群。 而作为实时处置配套,Kafka和Rabbitmq之间我还是偏向于Kafka。在Kafka搭建之前,先搭建zookeeper集群,zk是kafka的依靠组件,用来记录一些元数据。 下图号令操纵就是消耗写入Kafka的数据。  我们要做的就是将数据库/数据仓库中的离线数据,转换为数据流(Data Stream),作为生产者实时写入到Kafka中。 我们开辟的Spark/flink法式作为消耗者实时读取Kafka中的数据,实时处置并数据计较成果。以下图,为SparkStreaming的法式监控页面。 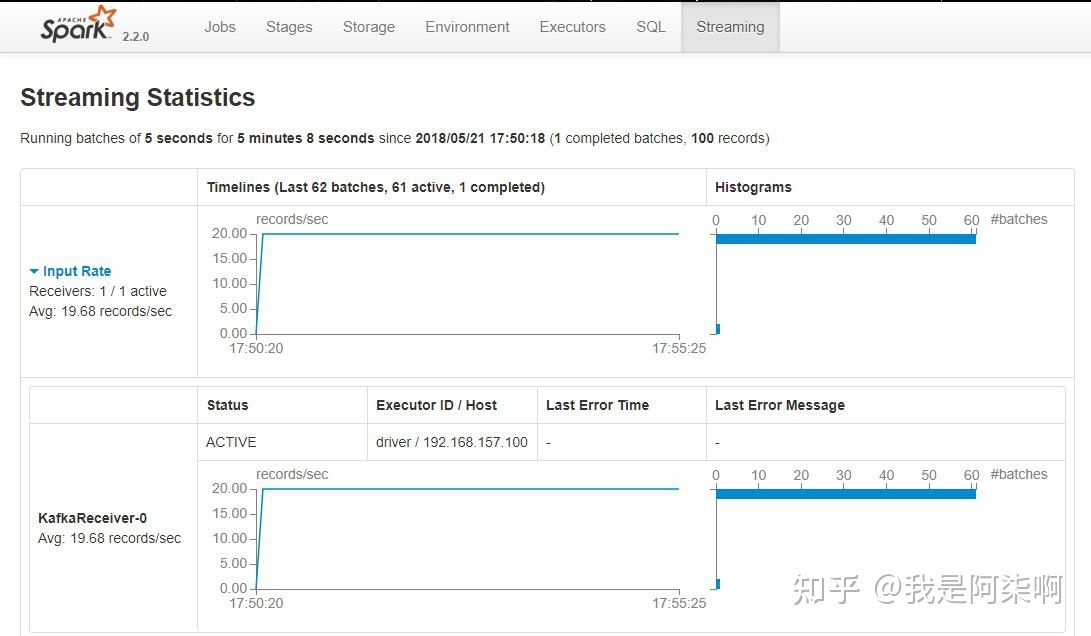 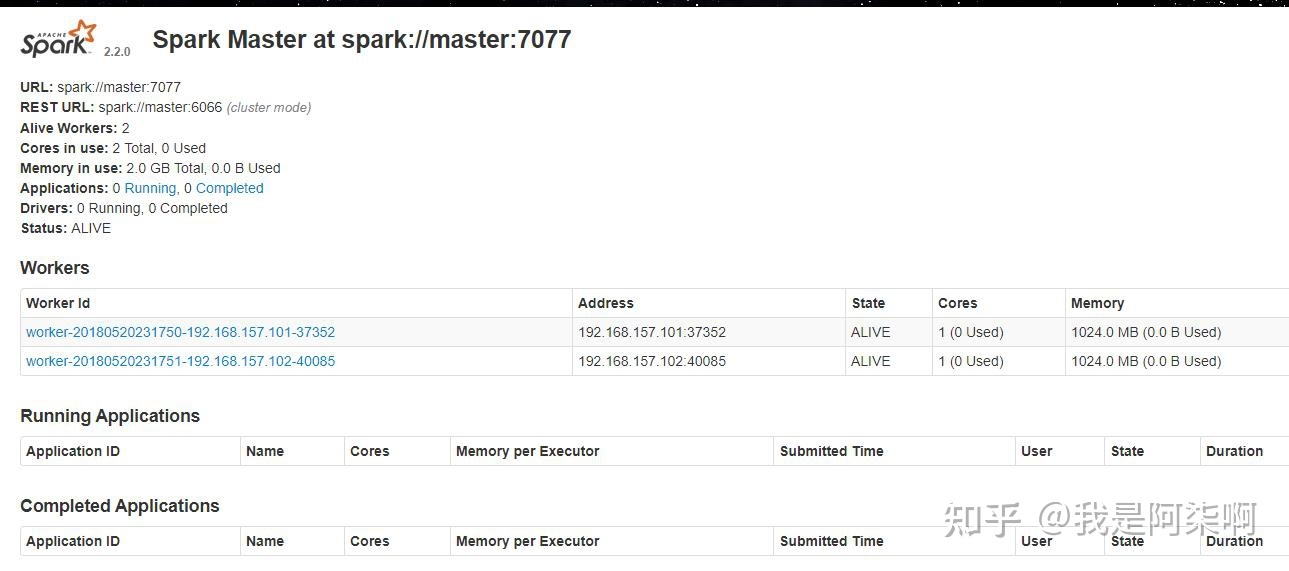 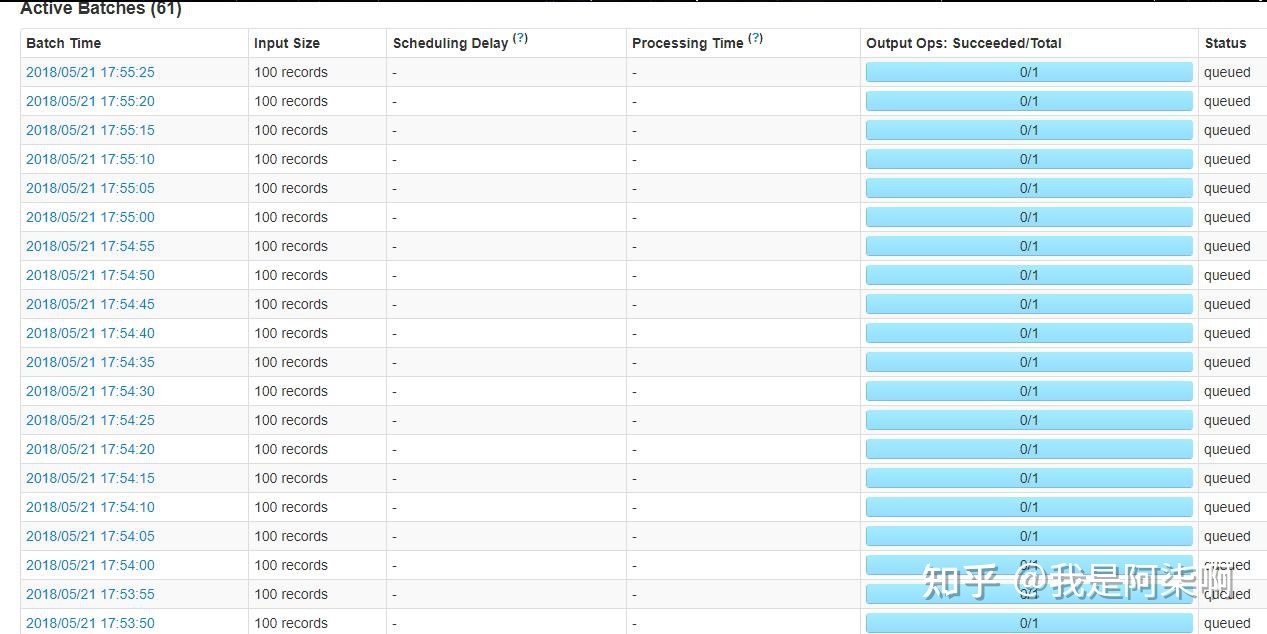 SparkStreming法式,可以利用Java、Scala、Python开辟,可是挑选Scala比力好一些。一是Scala的语法结构更贴合流式处置,二是源码都是Scala写的。 Flume - 数据交换神器当初刚打仗Flume的时辰,真的没玩大白,云里雾里的。后来深入研讨了一下以后,数据在oracle、MySQL、Kafka、HDFS以及其他存储平台上,便可以停止同步。不外MySQL和oracle需要自己界说Source和Sink。 Flume的简单之处在于设置化。当初我将数据从MySql抽取到Kafka,部分派置以下。 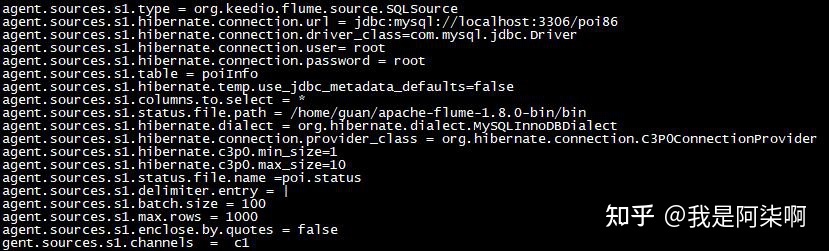 顺带一提,在大数据量的情况下,Flume很多参数还是需要调的。当初我将1W亿/天的数据从Kafka落地到HDFS的时辰,写了几千行的设置,调了很多参数。 3. 数据展现最初就是前台的数据展现了,利用了Springboot和Vue做了一个POI数据治理系统。首要实现分类查询和POI搜索标点舆图展现功用。 可是这个系统,我只找到了登录页面和舆图搜索标点的截图了....   数据治理系统发挥的空间还是挺多的,比如页面款式的优化,再比如前台可以利用Node + Vue,后端利用Springboot来实现前后端分手架构。 结语主如果给大师供给一个大数据平台结业设想的根基思绪,很多细节的地方还可以优化。我们也不难发现,这里的大数据集群都是自力安装的,我们一样可以利用Ambari停止同一的安装、治理、启动、状态监控。 比来也是在研讨Ambari,前几周刚花了一个星期,完成了Ambari2.7.5的编译安装工作。前期的方针是「配合docker在一台机械上完成大数据集群的搭建工作」,固然这里主如果玩,构建测试情况,性能啥的就不要斟酌了哈。 忙完这一阵,完成Scrapy系列文章,就起头动手预备大数据平台系列文章的编写。期待下一次相遇。 |



 微信扫一扫
微信扫一扫