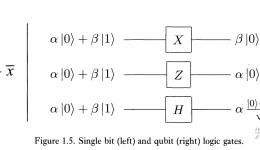
|
进修大数据不成不知的五种大数据框架,码笔记分享大数据框架Hadoop、Storm、Samza、Spark和Flink五种大数据框架详解: 一:Hadoop大数据框架 Hadoop 大数据框架?第一映入视线的就是这枚大象Hadoop,Hadoop是一个由Apache基金会所开辟的散布式系统根本架构,它是今朝利用最普遍的大数据工具,Hadoop具有容错率和极低的硬件价格。 Hadoop是成为了一个广漠的生态圈的批处置框架,Hadoop提出的Map和Reduce的计较形式简洁而文雅,它实现了大量算法和组件。可是,由于Hadoop的计较使命需要在集群的多个节点上屡次读写,是以在速度上会稍显优势,可是Hadoop的吞吐量也一样是其他框架所不能匹敌的。 二:Storm大数据框架Storm由Twitter开源而且托管在GitHub上的,Storm大数据框架与Hadoop的批处置形式分歧,Storm采用的是流计较框架。但Storm与Hadoop类似之处是也提出了Spout和Bolt两个计较脚色。 举个浅显的例子来说明Storm和Hadoop的分歧之处,Hadoop类似水桶,而Storm类似水龙头,想要获得水,Hadoop是一桶一桶的去扛返来,而Storm只需要翻开水龙头就行了。Storm流计较框架利用的是内存,提早上具有上风,可是不会持久化数据。 Storm对Java、Ruby、Python等说话都有很好的支持。 三:Samza大数据框架Samza大数据框架与Storm一样都是流计较框架,Samza必须和Kafka共用,Samza今朝只支持JVM说话。 四:Spark大数据框架 Spark和Flink Spark大数据框架是一种夹杂式的计较框架,Spark自带实时流处置工具;Spark也可以与Hadoop集成取代MapReduce;甚至Spark还可以零丁拿出来借助HDFS等散布式存储系统摆设集群。 Spark的运算速度与Storm类似,Spark的速度大约为Hadoop的一百倍,而Spark的本钱要比Hadoop低,可是Spark今朝还没有Hadoop具有上万级此外集群,所以现阶段将Spark和Hadoop搭配起来利用是比力不错的计划。 五:Flink大数据框架Flink大数据框架也是一种夹杂式的计较框架,Fink与Spark相反的地方在于Fink重点在于处置流式数据,今朝Fink还不算成熟。 |



 微信扫一扫
微信扫一扫