|
作者 | Tina
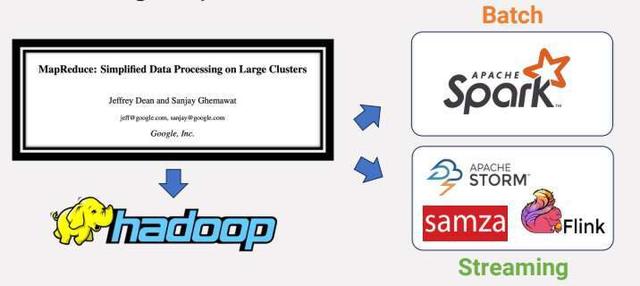
十年的循环,正如大数据的成长一般,它既是一个循环的竣事,也是崭新的起点。大数据在曩昔的二十年中兴旺成长,从无到有,突起为最具爆炸性的技术范畴之一,逐步演酿成为每个企业不成或缺的根本设备。但是,在这个时辰,我们不由要问:当前的大数据架构能否已经趋于完善?2023 年,陪伴着野生智能的跃变式爆发,数据平台将若何演进,以顺应未来的数据利用处景? 这并非简单的题目,更是一个关乎企业保存与成长的命题。在曩昔的十年中,我们目击了 Spark、Flink 和 Kafka 等系统的突起,它们成为大数据范畴的支柱。但是,现在能否有新的气力崭露头角,希望应战它们的职位?2023 年,大数据范畴有哪些本色性进步吗? 在 2023 年年关盘点之际,InfoQ 有幸采访了大数据范畴的资深专家,包括关涛、李潇、王峰(莫问)、吴英骏、张迎(按姓名拼音排序)。他们配合探讨了数据仓库技术的演变进程,深入分解了技术快速演变所带来的应战。在此次专访中,我们将揭露技术变化的背后缘由和逻辑,为大师显现大数据范畴的现状以及未来能够的成长偏向。 突如其来的革新和质疑?流存储 Kafka 诞生在 2011 年,而流计较 Flink 到今年也恰好满了十年。 十年前,软件范式是操纵虚拟化技术来发挥硬件性能。此外,云办事也只是刚刚兴起,存算分手等云原生概念尚未提高。 现在时过境迁,一切都在快速变化。现今的利用法式天天可以处置多达数万亿个事务,保护数 TB 的数据。硬件的迭代速度缓慢,相对十年前的 SSD,NVMe 速度提升十倍,价格也降至本来的 20%。S3 越来越多地被用作根本设备办事的焦点持久层,而不但仅是作为备份或分层存储层,例如 Snowflake、Databricks 等。
能否跟上硬件迭代速度,这是 Kafka 这样的成熟且架构已经定型的软件所面临的最大应战:具有众多用户,是以每个修改都需要花费更多的时候和精神去考证公道性,大大拖慢了迭代速度。 这也给一些草创公司带来了庞大的机遇:不需要用分层架构去实现存算分手,而是爽性用加倍极端点方式去做存算分手,即间接建立在 S3 工具存储之上。 基于工具存储的构建也大大下降了构建新数据系统的门坎,催生了一系列这样的“垂直”根本设备草创公司:今年诞生的兼容 Kafka 的 WarpStream、AutoMQ,客岁拿到 A 轮融资的 Neon Database、流数据库RisingWave,等等。 但是 S3 虽然价格廉价,能省本钱,但高提早是一个题目,数据系统构建者需要费点周折才能处置好需要低提早的工作使命。恰幸亏今年末,AWS 公布了 S3 Express One Zone,一种新的低提早 S3 存储种别,可以说是在正确的时候供给了正确的技术(今朝代价高贵)。 鞭策数据库和数据产物成长的首要身分首要有两方面。一方面是数据自己,另一方面是硬件的成长。S3 是硬件层面的变化,这势必会给大数据范畴带来庞大的变化。
“低提早 S3 的公布,对于我们这些处置数据根本设备营业的人来说,这是今年最大的一个消息。”RisingWave(risingwave.com)开创人 & CEO 吴英骏以为。 现在的大数据技术栈是真的难用吗?站在当前的时候点,对于大数据系统的易用性题目,采访嘉宾给出了“不够好”、“不够廉价”,“过分复杂”的评价,可以说现今的大数据技术栈是公认的“难用”。 大数据架构在曩昔冗长的 20 年里履历了从场景到系统的完整迭代。 大数据的起源可以追溯到谷歌的 MapReduce 框架,这标志着大数据的最初阶段。在此之前,数据库方面首要有一些顶级产物,如 Oracle、SQL Server 和 IBM DB2。Google 提出了一个通用的、折衷的计划,即不必采办 Oracle、DB2 或 Microsoft Server,利用简单的模子让大范围并行计较在具有大量普通计较机的科技企业中变得可行:操纵 MapReduce,不利用数据库,就能完成大数据计较,只不外用户需要去承当这些复杂性。 这里还有个大师能够忘怀的典故:数据库专家 David DeWitt 与 Michael Stonebraker(一样是图灵奖获得者)在 2008 年颁发了《MapReduce: A major step backwards》,对 MapReduce 停止了批评,称其为开历史倒车。 要充实操纵这些资本,MapReduce 提出的方式是,将底层编程接口封装成 Map 和 Reduce 函数以后,便间接表露给有编程经历的用户,让用户自己实现具体营业逻辑,并自己可以操控法式并行度等细节。用户不再是利用 SQL,而是利用 C 或 Java 等编程说话,需要承当编写底层代码的复杂性,处置更多的编码工作,这也意味着很高的进修壁垒,让很多人望而生畏。 在这时代,批处置和流处置在 Spark 和 Flink 的引领下率先成熟。
截图来历:https://zhuanlan.zhihu.com/p/662659681 近几年,交互分析,也称间接在线办事才能(Operational Analytics) 随 Clickhouse 等通用实时数仓风行,并已是究竟上完成支流客户的摆设。随流、批、交互三类计较场景成为标配,Lambda 架构也成为(国内的)究竟标准。Lambda 架构可以满足客户场景上的诉求,最大的缺点就是复杂:数据开辟、组件运维、数据治理均复杂。 究竟并不是一切公司都跟 Google、Facebook 或 Twitter 这样的大型科技公司一样,具有强大的工程团队,可以治理复杂的流处置系统来实现他们的需求。也并不是一切用户都像阿里和拼多多这样有着很是大的数据量,复杂的散布式系统障碍了十几或几十小我的小公司或一些传统企业的采用,对它们来说,这是一件本钱高、应战大的工作。 吴英骏以为,大数据架构里,如流处置,应当回归第一性道理了。 “现在的系统,诞生于十年前,与当下云时代设想的系统相比,从本质上来说必定是分歧的,这表白大数据生态在这十年间并没有获得本色性进步。” “在当前时辰,我们再设想这个系统时,必定会思考能否基于现有系统实现性能提升。” 说话层面,新系统需要供给一个更高条理的说话,比如 SQL 或 Python。别的,云上最焦点的一个点在于“存算分手”,站在现在这个时候节点上,新一代的系统从设想上的第一天起头就应当是“存算分手”的。跟分级存储架构纷歧样,现在的系统可以将所稀有据间接放到 S3,而不但仅是将历史数据放到 S3,那末这样便可以加倍极真个去实现存算分手,设想、实现和运维自然城市加倍简单。 RisingWave 于 2023 年 6 月公布了 1.0 稳定版本,并经过数月的大量性能测试,得出了“比Flink快10倍”的结论。 “性能比力不是关键,易用才是关键。基于工具存储并能在性能和效力方面获得提升,那必定是由于整体根本架构正在发生变化,这是一个焦点点。” 以 Spark 社区为例看易用性停顿:从 Python 到 AI“简单易用”一样是 Spark 社区的首要发力重点。在 Databricks 今年的 Data and AI Summit 主题演讲中,Reynold Xin 谈及了三个 Spark 社区在易用性的最新停顿。 首先,需要供给一套简单好用的 API。Python 和 SQL 已经成为了全部数据处置行业的支流说话。在曩昔几年,Python 已成为 TIOBE 指数显现的排名第一的编程说话,这类受接待的缘由来自于它的简单性和易学性,使其成为初学者和专家的首选说话。Python 的普遍库和框架简化了数据分析和机械进修中的复杂使命。各大数据系统都供给了它自己的 Python DataFrame APIs。PySpark 的 PyPI 下载量(https://pypistats.org/packages/pyspark)仅在 2023 年最初一个月就到达了来自 169 个国家的 2800 万次下载。为了方便 pandas 用户,PySpark 也供给了 pandas API 的支持。可以说,API 的简单易用已是大势所趋。出格值得一提的是,行将公布的 Spark 4.0 版本中,一个全新的 Python 的数据源接口被出格设想来夸大易用性。这一更新将使 Python 用户加倍轻松地建立和治理自己的数据源,进一步增强 Spark 平台的用户友爱度和灵活性。 Spark 社区在这方面继续发力,曩昔一年的一个首要项目,Spark Connect,引入了一种分手的客户端-办事器架构,答应从任何地方运转的任何利用法式远程毗连到 Spark 集群。这类架构的改良触及到了稳定性、升级、调试和可观察性多个方面。Spark Connect 使得用户可以在他们爱好的集成开辟情况(IDE)中间接停止交互式的调试,而且可以利用利用法式本身的目标和日志库停止监控。 其次,一个稳定成熟的数据系统必须具有一套稳定的 API,这也是 Spark 社区对 API 行为和语义的变更制定严酷标准的缘由,目标是让用户更顺畅地升级至最新版本。在上个月,最风行的 PySpark 版本就是最新的 Spark 3.5,这表现了用户始终偏向于利用最新版本的趋向。为了逢迎这一趋向,Spark 社区尽力保证向后兼容。 此外,毛病信息的标准化也是 Spark 社区曩昔一两年里的尽力偏向。虽然这看似技术复杂度不高,但这现实上是使系统加倍简单易用的根基需求。今年的 Spark 4.0 release 还会进一步标准化日志,以利用户可以更好地停止系统调优和代码调试。 而随着天生式 AI 的成长,未来 API 将变得加倍简单易用,自 ChatGPT 大风行到现在,我们发现它已经对 PySpark 有了深入的领会。这得益于 Spark 社区在曩昔十年里供给了丰富的 API 文档、开源项目和讲授资本。Spark 社区开辟了一个叫做 English SDK 的项目,将 Spark 专家的常识融入到 LLM 中。这样一来,用户便可以经过简单的自然说话指令来操纵 PySpark,而不需要自己写复杂的代码。这类方式让编程变得更轻易上手,进修进程也更简单。 流处置的演进从 2014 年诞生以后,Flink 已经建立了其在全球实时流计较范畴的职位。阿里、Amazon、Azure、Cloudera、Confluence 等众多企业都供给了支持和托管办事。 树大招风,现实上今年不止一家企业宣称在流处置技术上实现了 10-1000 倍的效力提升,假如这些技术确切可以在生产情况获得考证,像阿里、腾讯、抖音这样的大型公司每年能够会节省数十亿的机械本钱。虽然今朝还没有看到哪家公司在实在的生产情况中实现了这一结果,但这一趋向表白流处置技术的不竭创新将在未来带来更多的机遇和功效。与此同时,Flink的成长现状和未来演进则加倍引人关注。 流处置范畴能否有留给创业公司的机遇窗口?究竟上,Flink 一向在不竭完善和创新。Kafka 已经在贸易版中实现了一个“分级存储”架构来实现了存算分手的革新。同 Kafka 一样,Flink 也会从存算耦合转为存算分手的架构。 据莫问先容,今朝 Flink 也在不竭进修和自我革新,2024 年将是 Flink 项目标第一个十周年,Flink 社区也会公布 Flink 2.0 新的里程碑,完全的云原保存算分手架构、业界一流的批处置才能、完整的流批融合才能城市是全新的亮点。 莫问以为,随着云原生概念的慢慢提高,未来支流的计较负载一定是运转在 Cloud 上,全球范围内都是这个趋向,是以大数据架构也需要更好地适配云底座,操纵好云的弹性上风。存算分手将会是未来大数据架构的标配,不外存算分手在带来了诸多益处的同时也带来了额外的性能应战,今朝看来在对 latency 敏感的场景下,多级缓存和冷热分层将是对存算分手架构的有益补充,2024 年将公布的 Flink 2.0 也会采用这套最新的架构。 分级存储偏重于在计较节点上停止缓存,远端存储首要存储历史记录。相较之下,新的间接建立在 S3 上的系统将所稀有据完全存储远端,但也会形成性能的下降,这需要在产物设想方面去做一个权衡。 在存算分手上,Flink 会有一个迭代的进程,吴英骏以为,“大师的终极思惟都是同一的。假如我们将时候拉长,放到五年以后,我们能够会看到这两种系统现实上很是类似。在未来成长中,双方城市在自己的短板上停止填补。比如说,RisingWave 从第一天起就将内部状态放在工具存储上,而这意味着 RisingWave 需要思考若何下降工具存储所带来的高提早题目。而对于 Flink 来说,面临着利用当地磁盘存储状态而致使的大状态治理困难的题目。它能够需要引入一个分级存储的架构,来下降处置大状态计较时的资本消耗,同时避免系统间接挂掉。” “但在今朝一两年里,这两种系统在架构上照旧会有相当大的区分。架构的调剂不是一朝一夕可以完成的。” 新兴软件和成熟软件之间有了较劲,那末用户停止选型时,会关注哪些身分呢? 作业帮于 2019 年末调研 Flink 1.9 版本,并在 2020 年内部搭建了实时计较平台,现在流和批都在几千使命的范围。其大数据架构师张迎暗示,选型时,首要按照营业诉求,连系多云融合才能、成熟度、已有技术堆集、云厂商的支持力度、本钱等综合斟酌。 这几年利用大数据技术栈时首要有两点比力强的感受:生产情况的可用性、周边系统的扶植,这两点一定要跟得上。一个用户可以写出来几百个 SQL 使命,可是出了题目常常不晓得若何清查和改良。前面的工作,例如调优、自动化测试、日志、监控报警、高可用也都是围绕这类需求展开的。 本来需要写代码的实时使命,很多可以经过 SQL 完成。(在 2015 年后,随着流处置的成熟,流计较引擎纷纷挑选了支持 SQL 通用编程说话)。SQL 越来越复杂,设置越来越多,一定水平上还是将复杂度留给了数据流的构建者。“对于简单的数据流,开辟和运维都变得更简单了。而对于复杂且重要的数据流,我们的态度也一向是谨慎守旧为主,避免自觉求新。” 流处置技术进化偏向关于 SQL 的说法,跟莫问猜测流处置引擎未来进化偏向之一是分歧的,即:“周全 SQL 化,提升体验,下降门坎”。大数据处置从离线向实时升级的趋向已经建立,大量行业已经起头实时化升级,并获得很是好的营业收益。为了让更多用户可以享遭到实时流计较带来的代价,流处置引擎需要进一步提升端到真个易用性,周全 SQL 化 ,提升用户体验,下降利用门坎,让流计较可以在更多场景和行业中被生产利用起来。 云原生架构的不竭成长,也同步鞭策了数据湖存储计划的加速落地。数据湖具有的开放和本钱上风,必定使得越来越多的数据流入湖中,从而成为自然的数据中心,湖上建仓的 Lakehouse 架构正在成为支流,下一步客户一定是希望数据在 Lakehouse 中可以加倍实时的活动起来。 Apache Paimon 是从 Flink 社区中孵化出来的新项目,定位就是流批一体实时数据湖格式,处理 Lakehouse 数据实时化的题目。 基于 Flink + Paimon 可以构建出新一代的 Streaming Lakehouse 架构,让 Lakehouse 上的数据可以全链路实时活动起来。此外,基于计较和存储端到端流批一体的特征,也加倍方便用户在 Lakehouse 架构上实现实时离线一体化的数据分析体验。 “Paimon 是一个好的尝试,”关涛对此批评道。 之前 Flink 流批一体缺少对应的存储系统配合:Flink 自带的状态存储没法满足批处置通用数仓的需求,Paimon 则是补全这个短板的关键。 莫问指出,在实时流处置这条链路上,确切也存在一些新的机遇和变化。众所周知,Flink 和 Kafka 今朝已经别离成为流计较和流存储的究竟标准,但 Kafka 真的是最合适流分析的存储计划吗? Kafka 和很多消息行列类似,都是一种消息中心件,而非为大数据分析而生。例如:Kafka 并未对数据供给结构化的 Schema 描写, 也没法供给完整的 Changelog 语义,且 Kafka 中的数据时没法停止实时更新和探查分析的。 “但以上这些缺点,都是实时流分析需要的特征和才能,我们也正在思考这个题目,并摸索新的处理计划,希望可以在明年公布一款加倍合适流分析的流存储技术。” 2023 年,大数据技术栈的整体变化近些年各类分歧的大数据根本设备雨后春笋般的涌出,一方面为用户供给了多样化的挑选,但另一方面也为用户带来了幸运的懊恼。凡是情况下,用户要搭建一套大数据营业系统,需要很是多的焦点技术组件才能完成,少则三到五种,多则五到十种,这首要带来以下几方面的题目:
是以,未来数据技术的演进会逐步出现一些整合的趋向,走向加倍简洁的架构,焦点方针不可是让每个组件运转得更快,还需要斟酌为用户供给加倍简单、分歧性的开辟体验,以及全局最优的运维本钱。 从 Lambda 架构到 Kappa 架构的演进。当前数据分析平台的典型架构是 Lamdba 架构(由三层系统组成:批处置 BatchLayer,流处置层 Speedlayer,办事层 Servinglayer),随批、流、交互三种引擎诞生和成熟组装而成。这类架构的典型缺点,包括复杂度高,数据冗余度高,进修本钱/开辟本钱高档等。针对 Lamdba 架构的缺点,Kappa 架构应运而生。但多年曩昔了,Kappa 架构照旧更像是参考架构,并没有很多引擎/平台做到 Kappa 架构的要求。2023 年是个拐点,除了部分已有引擎起头拓展鸿沟相互渗透,还有一些新的设想和计较形式被提出。例如云器科技提出“通用增量计较”的新计较范式统:Lambda 架构到 SingleEninge,用一个引擎覆盖流批交互三种形式。 今朝业界支流的几款 Streaming、Batch 和 OLAP 引擎都起头相互渗透,例如:Flink 在发力流批一体、流批融合计较才能,Databricks 也基于 Spark 和 Delta 鞭策了 Delta Live Table 淡化流批的差别,StarRocks 在供给 OLAP 极致查询才能的同时,也起头经过物化视图形状供给对数据湖上数据的 ETL 处置才能。本质上各大支流计较引擎都在不竭扩大自己的才能鸿沟,淡化流、批、OLAP 鸿沟,希望为用户供给全场景分歧性的数据分析体验。这也是技术成长的必定趋向,各家城市逐步补齐短板,但也都有各自焦点的上风。 在比来几年的数据技术趋向演进的线路中,我们可以清楚的看到两个趋向变化:一是数据架构的云原生化。几近一切的大数据公司都挑选了拥抱云原生,推出了基于多云的 PaaS/SaaS 计较办事,从 Serverless 到 BYOC,为用户供给了在云上分歧范例的托管办事。二是数据分析的实时化。在技术上,数据的“实时化”包括了两个身分:数据的新颖度,以及数据的查询速度。用户也不再自觉地只追求速度,而是更重视新颖度、性能和本钱的平衡。在时效性上, Iceberg 赢得了更多关注,数据湖存储技术为我们供给了构建近实时(near-online)数仓的能够性,在本钱稳定的情况下可以支持更快、更多的流量数据。 数据集成上,SeaTunnel 成功结业,Flink CDC 3.0 演酿成以 Flink 为根本的端到端流式 ELT 数据集成框架。比如作业帮今朝首要在利用 SeaTunnel 以下降异构数据源间数据处置的开辟本钱。 社区希望能表格式可以同一,但现实还有一段路要走。 Lakehouse 平台在数据仓储范畴的利用正敏捷增加。这反应了一个重要的趋向:构造正从传统的数据处置平台过渡到加倍灵活、集成和效力更高的现代数据架构。据 2023 年 MIT Technology Review Insights 报告,全球 74%的首席信息官(CIOs)暗示他们已经在利用 Lakehouse 架构。自 Databricks 在 2020 年推出此概念以来,Lakehouse 作为一个新种别获得了普遍的采用。几近一切还未利用 Lakehouse 的首席信息官都计划在未来三年内摆设此类平台。 有专家以为,Lakehouse(湖仓一体)和 Iceberg 表格式已成为究竟标准。可是,当前按照 Slack users、 Github Stars、Github PRs、Github Forks、Issues 各个目标显现,Delta、Hudi 和 Iceberg 还是三分全国。虽然 Delta、Iceberg 和 Hudi 起源地分歧,可是各个社区都在尽力地提升开源社区的活跃度,让用户社区和开辟者社区加倍健康的成长。随着社区的合作加速,根本功用的差别在不竭削减。 三种表格式(Table Format)均基于 Apache Parquet 数据格式,但这些格式各自会建立出类似、但又不尽不异的元数据,从而影响数据向利用法式和分析工作负载的表达方式。成果就是,Delta、Hudi 和 Iceberg 之间存在一定的不兼容性。表格式的终极同一还有难度,未来还得看哪类表格式能给出更好的性能、更好的易用性和更延续的创新才能,接下来的一年必定加倍出色。 头部的云厂商的产物都或多或少地支持分歧的表格式。Snowflake、BigQuery、Athena 都已支持 Iceberg,而微软和 Databricks 都以 Delta Lake 为首要存储格式。由于当前数据处置引擎的格式支持缺点,用户不能不将数据以分歧格式存成多份。格式的兼容性读写会是未来一个值得关注的偏向。比如 10 月份公布的 Delta Lake 3.0 增加了 Delta UniForm 通用格式,Delta Uniform 自动为 Iceberg 和 Delta Lake 天生元数据,供给了一个实时数据视图,而底层它们同享的同一份 Parquet 数据,是以用户可以避免额外的数据复制或转换。别的,同时能支持 Hudi、Iceberg 和 Delta Lake 的元数据自动转换和天生的 XTable 也于 2023 年末正在申请进入了 Apache 孵化器。 GenAI 来了不管是至公司还是小公司,大师都渴望从天生式 AI 的高潮平分到一杯羹。固然,作为至公司,不管是 Databricks 还是 Snowflake,它们确切更有气力来停止天生式 AI 的开辟。 今年 Databricks 不但率先公布了开源可商用的大模子 Dolly,还于 6 月底公布以 13 亿美圆的价格,收买天生式 AI 公司 MosaicML 。 在 LLM 办事方面,对数据栈的依靠首要集合在常识库的构建和查询上,包括但不限于向量数据库。有人以为在短期内很丢脸到深条理 AI 对数据湖或数据仓库方面带来严重变化,但也有人以为数据是办事于 AI 的:大数据是燃料,大模子练习已经涵盖了大量已有的大数据技术,而数据湖则作为存储系统在其中饰演重要脚色。 Databricks 李潇对此也停止了诠释,他以为数据湖仓(Lakehouse)的感化是为 GenAI 供给了一个集合、高效和可扩大的数据存储和治理情况。它连系了数据湖的灵活性和数据仓库的高性能,支持结构化和非结构化数据的存储和处置,这是 AI 利用的数据需求的基石。 “今年,Databricks 的最猛停顿首要表现在将野生智能集成到数据平台中。“ 作为大数据行业里一个很是重要且典型的企业,Databricks 在 GenAI 也反应了全部大数据行业的技术演进。现在我们可以经过它在数据智能平台投入来看看天生式 AI 将对数据和分析发生的影响。 Databricks 是由一群 Apache Spark 的原创者所建立。Spark 的诞生阶段,始于 2010 年,标志着 Hadoop 技术时代的竣事。它的出现大幅下降了大数据处置的门坎,使得大数据起头与机械进修和野生智能连系,成为同一的分析引擎。2020 年,Lakehouse 架构的推出打破了传统数据湖和数据仓库的界限。Lakehouse 架构连系了数据湖和数据仓库的最好元素,旨鄙人降本钱并加速数据及野生智能项目标实施。Lakehouse 架构建立在开源和开放标准之上,它经过消除历史上复杂化数据和 AI 的孤岛,简化了数据架构。 而现在,则是到了天生式 AI 大潮下的 Lakehouse 阶段。Databricks 构建了一个基于数据湖仓(Lakehouse)的数据智能平台(Data Intelligence Platform),该平台的方针是实现数据和 AI 的平民化,利用自然说话极大简化了数据和 AI 的端到端体验。它操纵天生式 AI 模子来了解数据的语义,并在全部平台中利用这类了解。可以让用户可以在连结隐私和控制的同时,重新起头构建模子或调剂现有模子。 同时,Databricks 还供给了 Unity Catalog 数据治理工具来确保数据的质量战争安。Databricks 还于今年推出了 Lakehouse Federation (联邦查询) 的功用,用户可以跨多个数据平台(如 MySQL、PostgreSQL、Snowflake 等)发现、查询和治理数据,而无需移动或复制数据。别的,Databricks SQL(Lakehouse 上的无办事器数据仓库)利用量也获得了大幅增加。 Databricks 以为,在未几的未来,每个范畴的赢家都是那些可以最有用操纵数据和 AI 的,并深信对数据和 AI 的深入了解是每个赢家的必备技术。 未来的大数据架构将是一个高度集成、智能化和自动化的系统,它可以有用地处置和分析大量数据,同时简化数据治理和 AI 利用的开辟进程,为企业供给合作上风。 “未来的大数据架构,我们可以称为‘数据智能平台(Data Intelligence Platform)’。它正是顺应了两个首要趋向:数据湖仓(Data Lakehouse)和天生式野生智能(AI)。”李潇暗示。 这一架构建立在数据湖仓的根本上,它供给一个开放、同一的根本,用于所稀有据和治理,由一个了解用户数据怪异语义的数据智能引擎(Data Intelligence Engine) 驱动。这是相对现有 Lakehouse 架构下的,最大的冲破。 智能化方面,这个引擎能了解客户数据的怪异语义,使平台能自动优化性能和治理根本设备。操纵简化方面,自然说话大大简化了用户体验。数据智能引擎了解客户的说话,使搜索和发现新数据就像询问同事一样简单。此外,自然说话还助力编写代码、纠错和寻觅答案,加速新数据和利用法式的开辟。 在隐私庇护方面,数据和 AI 利用需要强大的治理战争安办法,特别是在天生式 AI 的布景下。供给一个端到真个机械进修运维(MLOps)和 AI 开辟处理计划,该计划基于同一的治理战争安方式。这答应在不妥协数据隐私和常识产权控制的情况下,实现一切野生智能方针。 总的来说,未来的大数据架构将加倍重视智能化、操纵简化和数据隐私,为企业在数据和 AI 利用方面供给合作上风。这将使企业能更有用地操纵数据,鞭策创新,同时庇护数据平安和成长 AI 技术。 采访嘉宾简介(按姓名拼音排序):关涛,云器科技结合开创人 &CTO 李潇,Databricks 工程总监、Apache Spark Committer 和 PMC 成员 王峰(莫问),Apache Flink 中文社区倡议人、阿里云开源大数据平台负责人 吴英骏,RisingWave(risingwave.com)开创人 & CEO 张迎,作业帮大数据架构师 更多阅读: 王峰(莫问)笔墨 QA 采访:https://www.infoq.cn/article/zK6T1A3HfolPsktP2Z1Z 李潇笔墨 QA 采访:https://www.infoq.cn/article/qcUuAu70UGm5AzO3g9MR 参考链接: 利用工具存储,数据湖才能重获新生:https://www.infoq.cn/article/JYoI8SgLbEdY68lWN5J4 数据库的下一场反动:进入工具存储时代:https://www.infoq.cn/article/5wczTd6ItqtwYdrHhHWy 上云还是下云:章文嵩博士解读实在的云原生 Kafka 十倍降本计划:https://www.infoq.cn/article/f4hJdZqtKAQdJvCKQYq7 RisingWave:重新界说流处置之旅:https://zhuanlan.zhihu.com/p/672964437 离别无停止性能 PK,带你看懂 Flink 真正技术演进之路:https://zhuanlan.zhihu.com/p/647747291 Single Engine + All Data :云器科技推出基于“增量计较”的一体化湖仓平台:https://mp.weixin.qq.com/s/wnHr7ucatvCMu2I6oW_T9Q 原文链接:https://www.infoq.cn/article/c5xjuPCzyo1AcZWR2QKU |



 微信扫一扫
微信扫一扫