|
匿名
发表于 2023-3-20 10:50:45
阅读模式


|
| |
| |
|
lovesbaobao
2023-3-20 10:52:44
显示全部楼层
| |
|
norris_vip
2023-3-20 10:54:07
显示全部楼层
| |



我是卢松松,点点上面的头像,欢迎关注我哦! 随着上面的一声令下(工信部要求所有APP、小程序进行备案),各大互联网大 ...



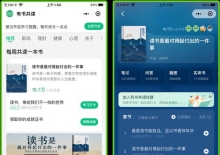
今日,闲鱼官方微信小程序正式上线。其首页界面与闲鱼的APP版本极为相似,功能上也基本一致。小程序提供了所有必要的 ...


50个微信小程序,后悔没有早点收藏!50个微信小程序,后悔没有早点收藏!50个微信小程序,后悔没有早点收藏! ...

如果您无需下载和管理即可获得像原生 iOS 或 Android APP 一样流畅的体验会怎样?腾讯通过微信小程序实现了这一替代方 ...


随着移动互联网的普及,微信小程序作为一种新型的应用形态,受到了广泛的关注和追捧。对于企业和个人而言,开通微信小 ...






【案情回顾】 徐某的报警称其被一个语音红包小程序骗走50块钱。一周前群聊里出现个大红包,徐某随即打开一看,原来是 ...






微信小程序作为一种新型的应用程序形态,自推出以来就引起了广泛的关注和争议。有些人认为它是未来的趋势,而有些人则 ...

随着移动互联网的快速发展,越来越多的企业和商家都在微信小程序上开展业务。而他们也希望可以通过微信小程序模板快速 ...


盼望着盼望着,国庆八天假期终于到了,想出去玩又被人山人海劝退,整天待在家里又很无聊,哒哒找了几款不错的微信小程 ...
本文素材来自于网络,若与实际情况不相符或存在侵权行为,请联系删除。 现如今,手机上的应用程序多不胜数,占用大量 ...
现在大家都把微信当成百宝箱来用,若你还傻傻只用它来聊天和支付可就太可惜啦... 跳一跳玩过吧?羊了个羊玩过吧?微信 ...
随着手机APP的功能越来越丰富、体积越来越大,占用的内存越来越大。那如何才能既能使用体验感良好,但又不占用内存呢 ...



虽然微信经常被大家吐槽,但不妨碍微信小程序成为一个好文明。 得益于微信上庞大的小程序数量,我们现在无论是衣 ...
很多朋友都喜欢微信小程序,可能是因为使用方便,不需要安装。下面我就来分享7个啧啧称赞的微信小程序,免费且实用, ...

随着微信越来越普及,微信小程序成为必不可少的功能,它实现了应用“触手可及”的理念,完全不用下载,占用内存空间, ...
登录微信公众平台 注册入口1:微信公众平台 点击 -> 微信公众平台 Tips: 请注意!一定要选择【小程序】!选择 ...
微信上有很多好用的小程序,但是隐藏的非常深,很多人都不知道。今天给大家分享8个让人爱不释手的微信小程序,个个好 ...

上海公共交通卡股份有限公司介绍,“一码通行”再升级啦!自即日起,用户只需在微信App内搜索打开“乘车码”微信小程 ...
很多朋友对微信上的小程序赞口不绝,主要是太方便了,不用安装就能使用。今天给大家分享6个好评如潮的微信小程序,个 ...
相信很多朋友都喜欢用小程序,免安装,直接使用,非常方便。今天给大家分享9个视如至宝的微信小程序,每一个都让人流 ...
现在的手机App体积越来越大了,不妨把目光转移到微信小程序上。今天给大家推荐8个免费好用的微信小程序,个个都是精 ...

我们每天使用微信,其实上面隐藏了很多功能。下面给大家推荐7个超实用的微信小程序,满足工作、生活、学习各种需求。 ...
来源:职场办公技能 我发现大家特别喜欢用微信上的小程序,主要是便捷,不用安装就能打开使用。今天再给大家推荐8个 ...

微信上的小程序非常方便,打开微信就能是使用,省去了安装的步骤。下面分享8个让人爱不释手的微信小程序,个个好用不 ...
最近互联网上的AI人工智能非常火热,你都接触过哪些AI技术?下面给大家盘点6个人工智能微信小程序,好用且免费,个个 ...


在已有 Taro、Uniapp、chameleon 等成熟框架的如今,如何看待饿了么开源的自研多端框架 MorJS?对比其他框架他有哪些 ...
文丨语鹦企服私域管家原创,未经授权不得转载 小程序凭借着平台的优势,成为了商家在私域运营中传播载体。商家在社群 ...


微信上的小程序非常便捷,直接打开就能使用,还不占手机内存。今天我来分享8个宝藏级的微信小程序,个个好用不要钱, ...



今天是一期微信小程序分享笔记,不想下载软件的小伙伴们赶紧看过来,这些好玩有趣的小程序你一定要知道! MindNow 是 ...
大家有没有遇到过那种小程序,用过一次就让你彻底爱上了?下面给大家分享8个赞口不绝的微信小程序,免费又实用,还请 ...

有没有这样一款产品? 把您学校五湖四海的校友凝聚在一起,既能帮助 TA 们在生意和工作上双赢合作、成人达己,又能 ...

品牌:uniapp 语言:vue 类型:文章资讯博客 支持:小程序 ** 有需要的朋友记得关+赞+评,免费分享需要的来交流! ...

随着移动互联网的快速发展,应用程序已经成为人们生活中必不可少的一部分,而小程序和Flutter技术则是当前应用开发中 ...
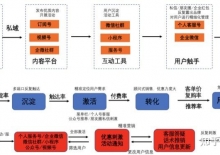
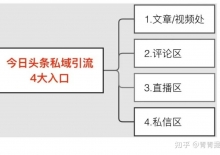
一时间几乎所有的商家都在构建私域,而构建私域的流量来源更多的是通过微信站外引流而来。 私域之所以被大家重视,并 ...


越来越多的朋友喜欢用微信小程序了,轻量级、免安装,打开直接使用,非常方便!下面这10个拍案叫绝的微信小程序,个 ...
【央视网消息】近日,意大利个人数据保护局宣布,从即日起禁止使用聊天机器人ChatGPT,并限制开发这一平台的OpenAI公 ...
一、基本介绍 MobileIMSDK - 微信小程序端是一套基于微信原生 WebSocket 的即时通讯库: [*]1)超轻量级、无任何第 ...

关注我的人都知道,我是有求必应的,前几天发了个无代码开发小程序的文,也没啥内容,但是也有朋友问我能不能分享 ...




本文为系列文章,建议没看过基础讲解的同学先看看:微信小程序最新大招——xr-frame尝鲜,基础图形讲解 全文目录:微 ...



微信小程序开发流程详细步骤! 点进这篇文章的小伙伴都是想做一个自己的小程序吗?没问题,我来给你介绍一下小程序开 ...
申请微信小程序=注册并认证小程序(拥有账号)+制作小程序(拥有前端界面)+上线小程序(微信能搜索到) 无论你是花店 ...

摘要:2022年已经过去,又到了总结小程序互联网发展变化的时间。 连续三年的疫情对每个人的工作生活提出考验,也推动 ...

也许我们都低估了OpenAI和ChatGPT。 自从ChatGPT去年11月推出并爆火,人们最关心的似乎是:这个强大的聊天机器人或其 ...
 微信扫一扫
微信扫一扫

 匿名
发表于 2023-3-20 10:50:45
匿名
发表于 2023-3-20 10:50:45






















